Oct 21, 2020 Winners' reports and presentation videos have been released. Winners presentation video
June 12, 2020 The content of the prize has been decided.
Purpose
While it is said that Moore’s Law, which has played an important role in the development of IT technology, is stalling, with the arrival of the IoT society, it is expected that the number of IoT devices that will be required to respond instantly at hand will increase. Therefore, the demand to realize innovative AI edge computing that uses AI to handle such processing is increasing. Since 2018, the Ministry of Economy, Trade and Industry (METI) and New Energy and Industrial Technology Development Organization (NEDO) has been holding the “AI Edge Contest”, which is to compete to solve problems with the intention of implementation using the real data for the purpose to discover excellent technologies and ideas and engineers who support them, and encourage new engineers to participate in this field.
The first contest was to compete the accuracy of algorithms with the theme of object detection and segmentation, the second one was on the theme of the implementation to FPGA, and this time for the third one is to compete recognition accuracy of the algorithm while paying attention to the model size and inference time with the theme of object tracking.
The 1st AI Edge Contest (Algorithm Contest (1))
The 2nd AI Edge Contest (Implementation Contest (1))
AI Edge Contest Official Website
Contest Outline
| Subject | Create an algorithm that detects a rectangular area in which objects are captured from the videos taken by a camera forward facing a vehicle and tracks the objects. |
| Data | (Train/Test) videos of a vehicle front camera (Train) Rectangular tag area labeled with objects, category and object ID |
| Identifying Target | Car, Pedestrian |
| Evaluation | For the models that clear the thresholds of the model size and inference time, determine the ranking based on the recognition accuracy of the prediction results. |
| Award, etc. |
1st Prize: 500,000 yen + Google Cloud Platform Coupon (100,000 yen) 2nd Prize: 300,000 yen + Google Cloud Platform Coupon (50,000 yen) 3rd Prize: 100,000 yen + Google Cloud Platform Coupon (50,000 yen) |
Subject
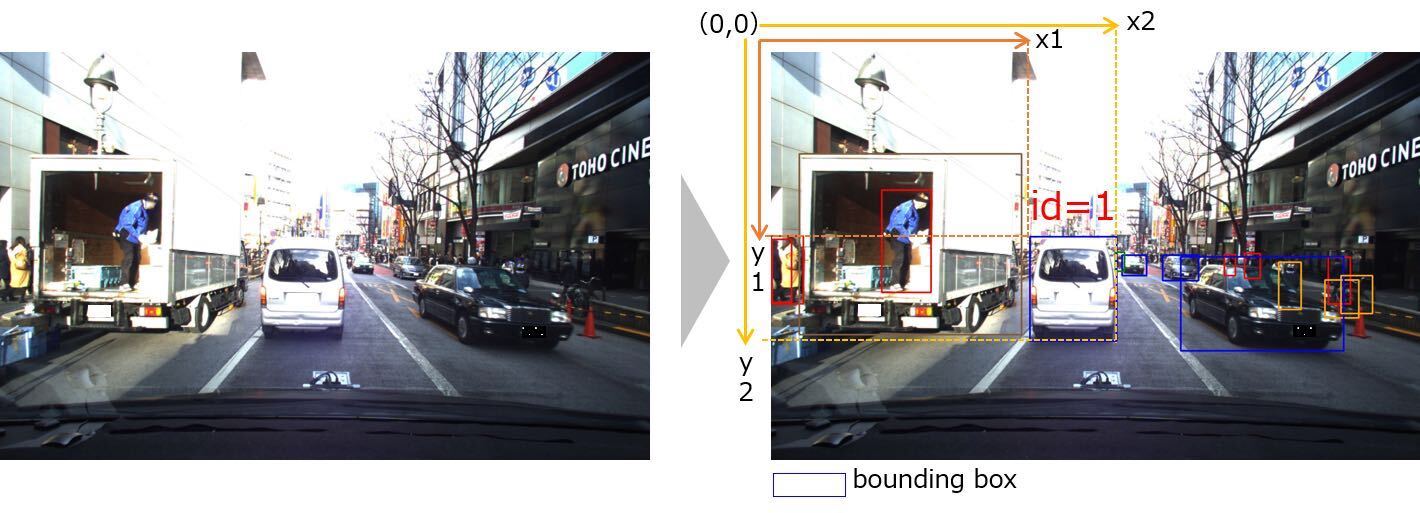
Allocate a rectangular area containing objects to be predicted as a bounding box = (x1, y1, x2, y2) to the video captured by the vehicle front camera, and give any unique object ID to the same object in each video. With allocations of multiple bounding boxes to each frame in the videos, the bounding box is represented by specifying four coordinates with the upper left corner as the origin (0,0), upper left coordinate of the object area (x1, y1), and the lower right coordinate (x2, y2).
However, the object to be evaluated (objects to be inferred) is limited to those that satisfy all of the following.
・There are two categories: “Car” and “Pedestrian”
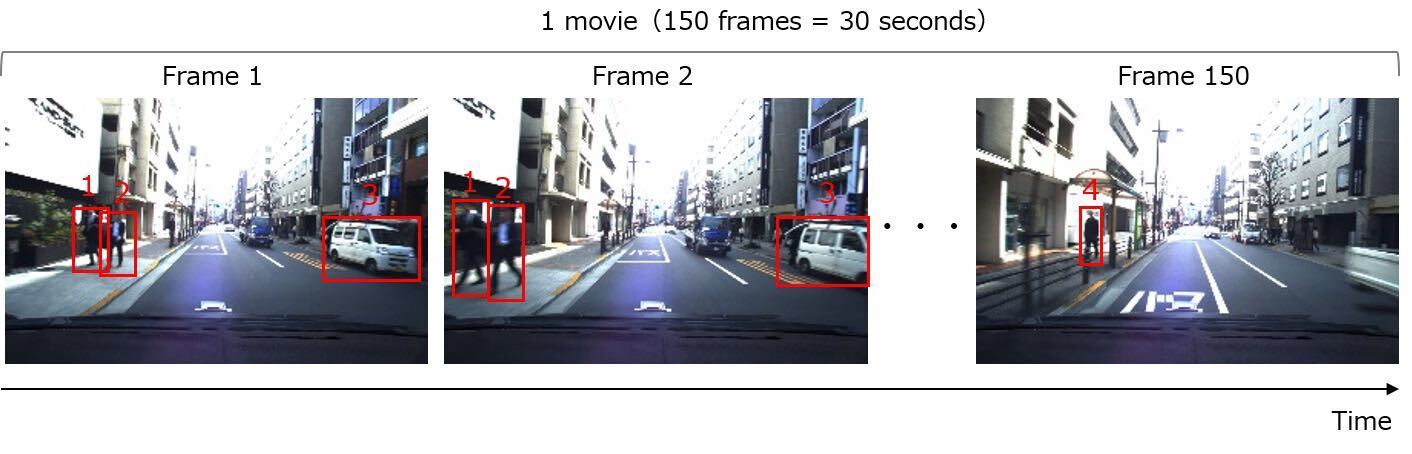
・Objects with 3 or more frames in each video (Frames do not have to be continuous)
・Objects with a rectangle size of 1024 pix² or more
*Even if an object appears in three or more frames in the video, if there are less than 1024 pix² or more in three frames, the object including the size of 1024 pix² or more will not be evaluated.
*Please note that if an object that does not meet the conditions is detected, it is considered as a false detection.
Data Details
| For Train | For Test | |
| Route | Tokyo (Shibuya – Akihabara) | |
| Time Zone | Day time | |
| Resolution | 1936 x 1216 | |
| FPS | 5.0 | |
| Category Types | Car, Pedestrian, Truck, Signal, Signs, Bicycle, Motorbike, Bus, Svehicle, Train | Car, Pedestrian |
| Number of Videos | 25 videos | 74 videos |
| Length of an videos | 120 seconds | 30 seconds |
| Number of Frames per video | 600 | 150 |
Travel Route





 Participation information is being registered. Please wait for a while.
Participation information is being registered. Please wait for a while.